License Plate Recognition
Contents
- Section 1: Project summary
- Section 2: Data set preparation
- Section 3: Architectures of neural networks
- Section 4: Software
- Section 5: Experimental results
- Section 6: Potential future extensions
- Section 7: Conclusion and discussion
Project summary
In this project, we will apply the deep learning techniques to solve the problem of license plate recognition (LPR).
For example,
when an image of the car plate license is given,we want the machine learning system returns us a
string of characters and numbers.
The overall procedure is summarized as follows:
- We firstly collect images containing one car plate licenses from online sources. In this step, we only consider
samples which
include seven characters or digits such as ZG790D0, KA596CJ, or ZG784FU.
- Next, to obtain high-quality data, we manually snip car plate license in images and do the pre-processing for the
cropped car
plate license including character and digits segmentation.
- After then, we design MATLAB programs to generate a numerical representation for these collected images with the relation:
feature data & label data.
- In our project, we design two different neural networks to train and test our data. One is to implement three convolution
layers and
the second is base on a deep residual learning framework. Furthermore, we use 80% of samples for training,
and the rest 20%
for testing.
- We have done several analyses based on results we get from two neural networks and finally obtain a good result through slight
changing neural architecture and adjusting parameters such as learning rate or batch size.
Automate plate license recognition is a technology that applies character and digits recognition system on images to read vehicle registration
plates. For example, the systems will alert police to record those cars which violate traffic laws or on a "hot list". At the beginning
of the project, we do not know how the recognition works, which architecture of NN should be used for the system, and how we can make our recognition
system or model more efficient? These problems are under our investigation.
Data set preparation
We use several datasets found on the internet, which include Medialab LPR database,
License Plate Detection, Recognition and Automated Storage, and
PlatesMania.com.
These images are mainly categorized into several types: images in close view, images in middle-distant view, dirt or shadows showed on car plate licenses,
and images shot at night.
The image in close view:

The image in middle-distance view:

Dirt or shadows showed on car plate licenses:


The image is taken at night:

To obtain a high-quality dataset, we decide to snip each car plate license from images manually and do segmentation. There are several samples below.
Example1:
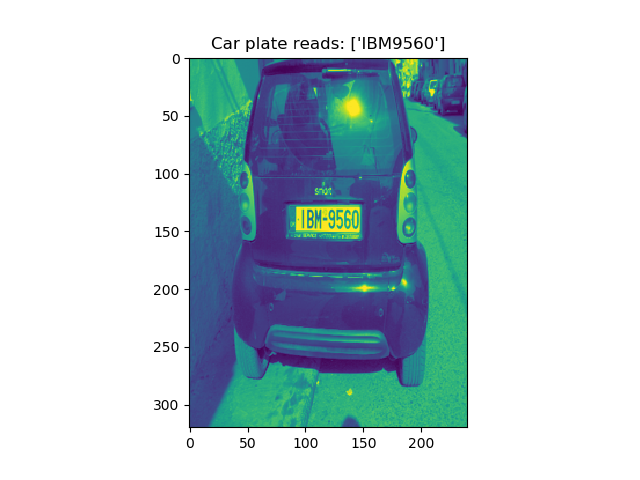
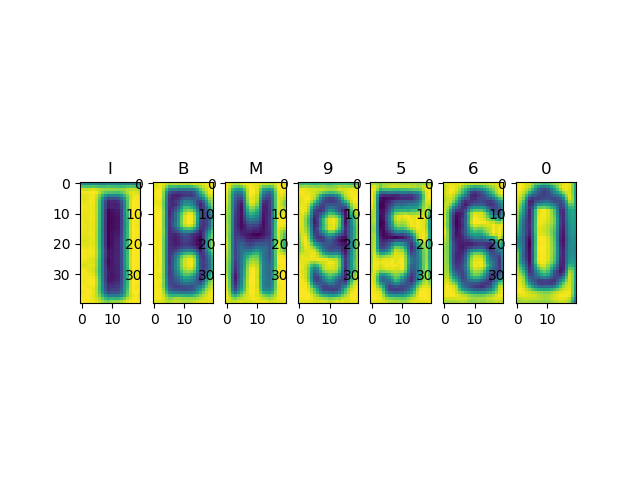
Example2:

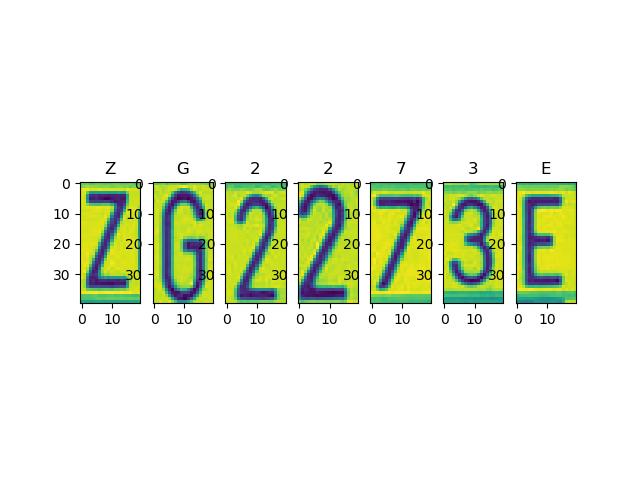
Example3:
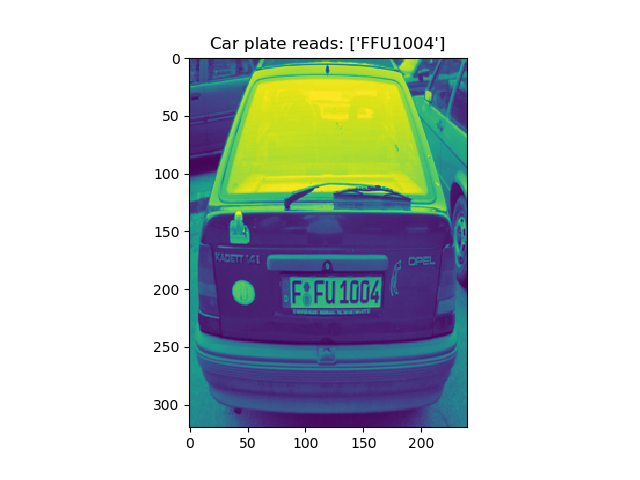

For the project, we have ten image sets and totally collect 476 pictures. After segmentation, there are total of 3808(476*8) images (one is the original picture, the rest are seven
characters or digits for one car plate license). collected_data(download here)
After then, we design four MATLAB programs called image_to_data.m, illustration.m, label_to_vector.m, and
vector_to_label.m to generate numerical respersentation of the dataset with relation feature data & label data.
For feature data:
- a. Each plate image is segmented to get 7 images of characters or images.
- b. All the 7 images are converted to gray images so that we can reduce the memory
needed for computation, and they are resized to be of the same size, i.e., 40 rows and 20 columns.
- c. For each of the 7 images, we reshape it to be an vector with 1 row and 800 columns.
- d. Finally, we will have 476*7 such vectors (476 plates, and 7 characters for each plate).
We will store them in a matrix with 476*7 rows (characters) and 800 columns (pixels).
- e. Starting from the first row of the matrix, every 7 consecutive rows form the features of a plate.
For example, the row index sets [1,2,3,4,5,6,7], [8,9,10,11,12,13,14] and [15,16,17,18,19,20,21] correspond to the first,
second, and third plate. However, the row index set [2,3,4,5,6,7,8] does not correspond to any plate, instead, it contains
some characters from the first plate and some characters from the second plate. Here we have assumed that the first row has
index 1.
For label data:
- a. For each image, we will consider its 7 characters one by one. For each character we create a one hot vector for it
- b. Since we have 10 choices of number digit and 26 choices of letters, we use a one-hot vector with 1 row and 36 columns to represent the label of a character.
The correspondence is as follows:
Character <-> position of ‘1’ in one-hot vector 0 <-> 1, 1 <-> 2, … A <-> 11, B <-> 12, …, Y <-> 35, Z <-> 36.
- c. Similar to the feature data case, we finally get a label matrix with 476*7rows and 36 columns. Each row represents a label of a character from a plate.
- d. Starting from the first row, every consecutive 7 rows will form the label for a plate.
For each image set, we use image_to_data.m to generate four files, Plate_Character_Labels_*, Plate_Labels_*,
Plates_Character_Images_*, and Plates_Images_*
(* points to the image-set number and we totally create nine image sets for the project). These four files for each image set are load-data for our neural network.
all_mat_data(download here)
Architectures of neural networks
Our two neural networks are mainly based on Convolution Neural Networks which is one of the popular deep learning models and can be trained via back-propagation algorithms.
Vanilla_CNN.py(the first neural network)
For the model, we use three convolutional layers and two fully connected layers.
The first convolutiona layer: conv1 + relu + maxpool1
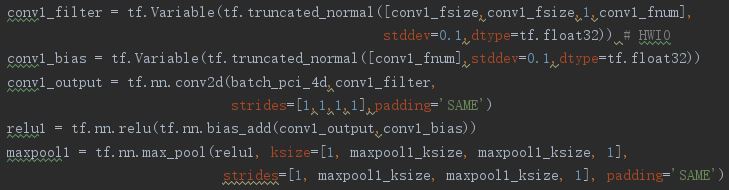
The second convolutional ayer: conv2 + relu + maxpool2
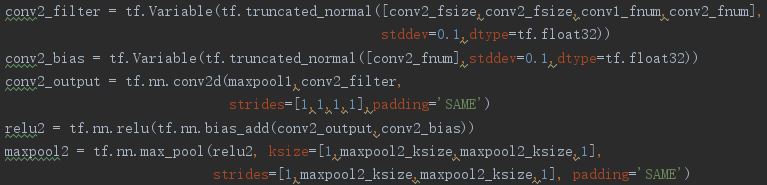
The third convolutiona layer: conv3 + relu + maxpool3
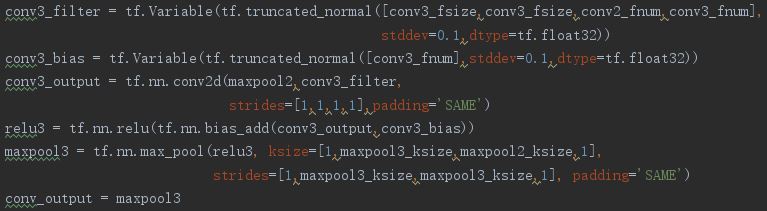
The first fully connected layer: fc1 + relu
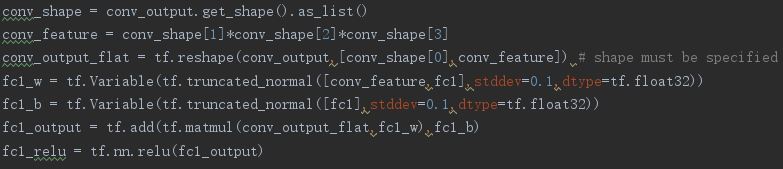
The second fully connected layer: fc2

Finally, we have the construction of loss, training accuracy rate, the testing accuracy rate

parameters we used for the neural network
conv1_fsize = 4
conv1_fnum = 20
maxpool1_ksize = 2
conv2_fsize = 4
conv2_fnum = 20
maxpool2_ksize = 2
conv3_fsize = 4
conv3_fnum = 20
maxpool3_ksize = 2
fc1 = 100
fc2 = 36
batch_size = 90
l_rate = 0.005
N_epoch = 500
vanilla_resnet_v3.py(the second neural network)
In this section, we also design a residual network to do the experiments, and compare the performance of these two network architectures a vanilla CNN network and a vanilla ResNet.
We analyze the paper Deep Residual Learning for Image Recognition by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun and find that
sometimes, deeper neural networks are more difficult to train; therefore, we try to present a residual learning framework to ease the training of networks. For the second neural
network, we try to use the residual learning functions regarding the layer inputs, instead of learning unreferenced functions.
The network we build for the second approach
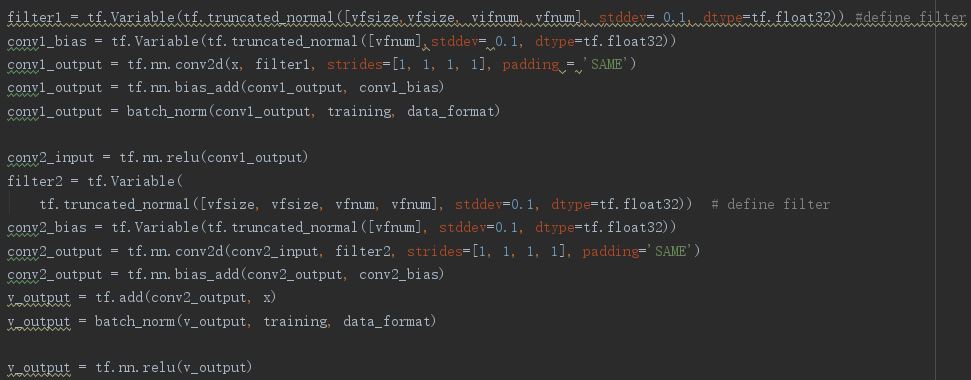
parameters we used for the neural network
vfsize = 3 //Filter size for each covolution layer in the block
vfnum = 16 //The number of filters for each covolution layer in the block
batch_size = 80
l_rate = 0.001
Next, We introduce how to train and evaluate the networks proposed. We will take the Vanilla_CNN structure as an example to illustrate the idea part by part.
- (1) training data and testing data separation: We do not directly sample over the plate character samples, and instead, we sample over the plate samples. Once we get the batch indices
of the plates, i.e., [1,4,9] (we use size 3 as an example to illustrate the idea), then we can get the batch indices of plate characters, i.e., [[1,2,3,4,5,6,7], [22,23,24,25,26,27,28],
[57,58,59,60,61,62,63]]. The samples corresponding this set of indices are used as the training data, and the rest is used as the testing data. The motivation for doing it this way is that,
if we directly sample over the plate character samples, then 7 consecutive characters may not every form a plate. For example, suppose we sample over the plate character samples and get an
index set [2,3,5,6,7,8,10,23,14,12,19,98,109,90], the plate characters corresponding to indices [2,3,5,6,7,8,10] do not form a valid plate. This sampling technique will also be used in the
training process. We refer this sampling strategy as 2-phase sampling.
- (2) batch samples sampling: The sampling technique here is the same as those mentioned above. Suppose we have a batch size (batch_size) for the plates, we sample batch_size plates from the total
number of plates. Then for each sampled plate, we find the indices corresponding to the 7 characters on the plate. Since we will train the neural network over the plate characters, then this means
we actually have a batch size value of 7*batch_size.
- (3) neural network training: Once we obtain a batch of plate characters (the batch size is 7*batch_size), the network can be trained in a way similar to the training of a network for the MNIST data set.
Some minor differences are: 1) our problem have 36 labels, while the MNIST data set has only 10; 2) when we obtain a batch of samples, our model requires a 2-phase sampling technique (first over the
plate samples and then over the plate characters), while the MNIST only requires a one-stage sampling. The loss is defined over the plate characters rather than plate. The intuition is that if we can
perform well on recognizing each character, then of course, we can perform well on recognizing 7 consecutive characters.
- (4) performance evaluation: We will the accuracy for recognizing both the plate characters and plates with in a batch. The evaluation of plate character recognition is the same as that in evaluating the MNIST
recognition accuracy, i.e.,(number of correct plate character recognition) / (batch_size*7). When evaluating the plate recognition accuracy, we will evaluate 7 consecutive plate character samples every time.
If for 7 consecutive plate character samples, there is only 1 wrongly classified character, then we treat it as a successful recognition of a plate. The motivation is that it would be unrealistic to expect the
successful recognition of the 7 characters since this actually requires a perfect recognizer, but allowing making one mistake is acceptable in practice. Once we get the number of correct recognition of plates,
then the plate recognition accuracy will be evaluated by (number of correct plate recognition) / (batch_size).
Software
- TensorFlow: it is an open-source machine learning library for research and production.
- OpenCV: it is a library of programming functions mainly aimed at real-time computer vision.
- catch_number_plate.py: when we run the program, we can automatically find a potential car plate
license
in an image and crop the license from the original image.
- adding_noise.py: it provides a function to add Gaussian noise to segmented characters or digits.
- rotation.py: it provides a function to tilt segmented characters or digits in any degrees.
- image_to_data.m: it is a MATLAB program. When we use it, we can generate a numerical representation
for
an image set with relation feature data and label data, which are loaded into the input of our neural networks.
- Vanilla_CNN.py: it is the first neural network we created. It has three convolutional layers and two fully
connected
layers. Furthermore, we have the construction of loss, training accuracy rate, and the testing accuracy rate.
- vanilla_resnet_v3.py: it is the second neural network we created. We apply the residual learning framework
instead of
learning unreferenced functions. We try to use the model to ease the training of networks.
Experimental results
In the training and testing process, we use three machines. The first machine is from the engineering lab with NVIDIA advanced GPU. It takes about 10 minutes to finish 500 epochs.
The second machine is from Argon hpc server.
It takes about 8 minutes to finish 500 epochs. The third machine is from a game laptop with NVIDIA GeForce GTX 1060M. It takes
about 41 minutes to finish 500 epochs. For three machines, we get almost the same result for loss
and accuracy of training and testing processing, so we just show one result about our
two neural networks.
Vanilla_CNN.py(the first neural network)
loss for Vanilla_CNN:
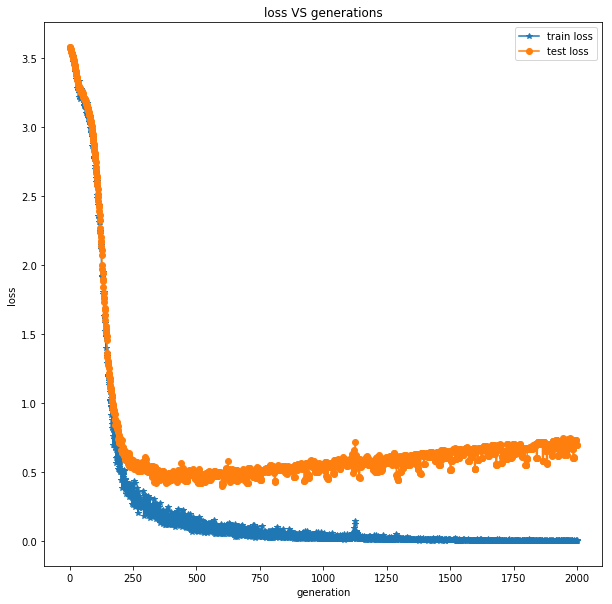
train loss: the training loss of character recognition in a batch
test loss: the testing loss of character recognition in a batch
accuracy for Vanilla_CNN:
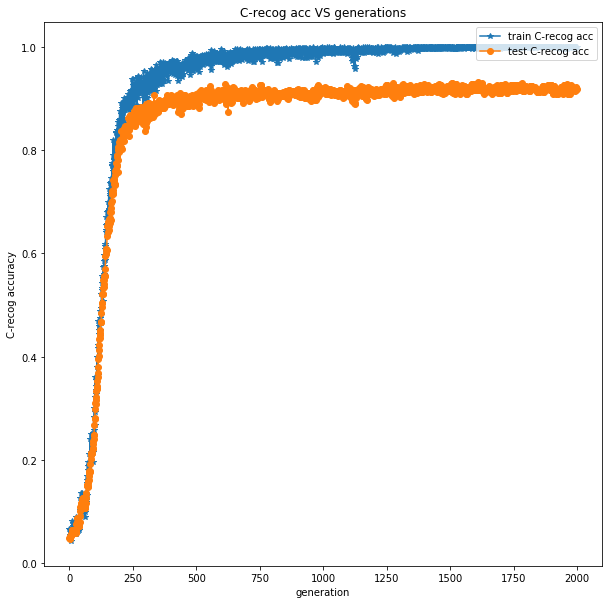
train C-recog acc (or C-recog train accuracy): the training character recognition accuracy in a batch
test C-recog acc (or C-recog test accuracy): the testing character recognition accuracy in a batch
From the loss plot of the vanilla CNN structure, the training loss can decrease to 0 as we increase the number of epochs, but the testing loss goes down quickly
in the very beginning and then goes up slowly.
This actually means that the vanilla CNN for our problem is slightly over fitting the data. This is actually also
what we expect since we have limited number of data samples due to the limit of a course length.
Fortunately, the over-fitting phenomenon is not severe, which
means we can still hope to get good generalization results. This is also validated by the accuracy plot of the vanilla CNN.
In the accuracy plot of vanilla CNN, we see that the plate character recognition accuracy in training process can be as high as 100% and the accuracy in testing
process can also achieve as high as around 90%.
However, in the vanilla residual network case, the results are different. As we can see in the loss plot, both the training loss and testing loss goes down simultaneously
as the number of generation increases. Though it
converges at a lower speed, the system seems to be more robust without large variance.
One interesting observation is that from the loss plot of vanilla residual network, we expect the loss can be further decreased when the number of generation increase.
But from the accuracy plot of vanilla residual network, the
accuracy seems to have been saturated, and no further improvements can be achieved. This is also the
reason we terminate the program with 1000 generations. Unfortunately, we haven’t found a good explanation for this.
From the comparisons of the results from a vanilla CNN structure and that from a vanilla residual structure, the former is more powerful in dealing with our problem
than the latter one. Apart from the difference of number of variables
used in two networks, we suspect the structure difference also accounts for the different performances.
For example, in the vanilla CNN structure, we do not take extra information by adding $x$ as the residual network does, and this
makes the vanilla CNN more aggressive
in searching for a better solution or network configuration.
We now present the plate recognition accuracy plot for the vanilla CNN case.
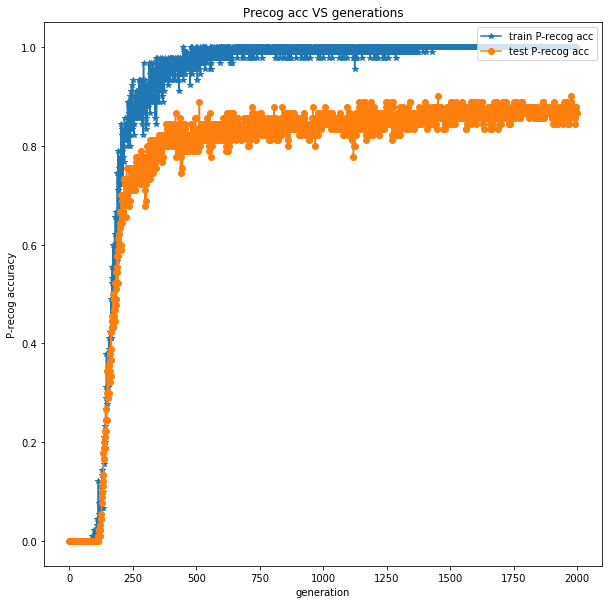
train P-recog acc: the training plate recognition accuracy in a batch
test P-recog acc: the testing plate recognition accuracy in a batch
From the plate recognition accuracy plot, we see that in the very initial tens of iterations, the accuracy remains 0 but the plate character recognition accuracy increases stably. This is reasonable since the plate character recognition task
is easier than the plate recognition, and the infant vanilla CNN can recognition some characters but cannot recognize any full plates. However, as the CNN becomes increasingly better tuned, it performs very will in both tasks.
vanilla_resnet_v3.py(the second neural network)
loss for vanilla_resnet_v3:
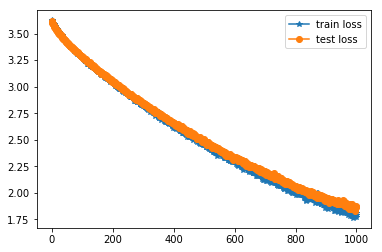
train loss: the training loss of character recognition in a batch
test loss: the testing loss of character recognition in a batch
accuracy for vanilla_resnet_v3:
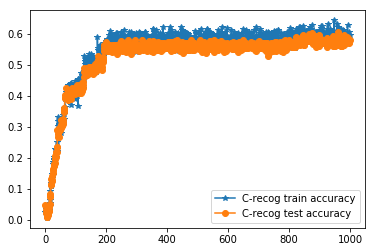
train C-recog acc (or C-recog train accuracy): the training character recognition accuracy in a batch
test C-recog acc (or C-recog test accuracy): the testing character recognition accuracy in a batch
According to results above, the performance of the second model is worse than the first model. We assume that deep residual function might not be appropriate to the model we use for the project.
After our analysis, we suspect that the degradation of training and testing accuracy result from several reasons. The first potential reason is that model is not easy to optimize, so it degrades
the accuracy of training and testing. The second reason might be that we are supposed to use a shallow architecture. we need to add more neurons to our layers and make our network wider. These assumptions
are still under our investigation. We need to take a long time to study residual function framework, so we take the question as one of our future extension.
Potential future extensions
Firstly, all collected data are pre-processed and segmented by our team manually. It spends us much more time on it. An interesting future extension can be designing another neural network to detecting the car plate and a third network to segment
the plate characters in an automatic way. By this, we can get a completely intelligent plate recognition system.
Another potential extension can be that using a more systematic way to design neural networks to solve the problem and compare their performances. Next, it would also be interesting to enlarge the data set and publish it as a benchmark for intelligent
transportation. To the best of our knowledge, there are not many such data sets for supervised learning in car plate detection, and car plate character segmentation. Since we have manually obtained the car images, car plate images, and car plate character
images, and annotated the data samples. They will be well suited for supervised learning tasks in intelligent transportation.
In this section, we briefly introduce some preliminary exploration in automatic plate detection and segmentation. Actually, in the beginning, we planed to design a python program called catch_number_plate.py
based on OpenCV to find a car plate license automatically and do the segmentation. However, our data come from different online sources, so there is no uniform standard. In 50% of the samples, we fail to find a potential car plate licenses in a image. There are several examples of success and failure
Examples of success:



Examples of failure:



What is more, our data set is of small size. We consider data set augmenting and further improve the performances of the model. We try to perturb our input by a very small amount.
We use two ways on our created data. The first way is to add noise to our dataset. We create a python program adding_noise.py to
add Gaussian noise on each segmented character or digit. The second way is to tilt all characters or digits we segment from each image. We create a python program rotation.py
to implment the second way.
Original data






Adding Gaussian noise







Tilting images







Conclusion and discussion
In conclusion, we successfully design and implement a license plate recognition system. After training processing, when an image set includes the car plate license is given,
our deep learning system can recognize these symbols.
In the project, we have two neural networks, so it is easy for us to compare and do analyses for our system. In our experiment, the first neural network(Vanilla_CNN.py) has a better
performance than the second approach(vanilla_resnet_v3.py). The accuracy of the first model almost reaches 1.0; however, the second model has fluctuated from 0.55 to 0.6. In fact, we
expect that residual function of the residual network can provide shortcuts to help with training, but the result is different. We guess that we have 36 classes for training images
and our architecture might be slightly simple in the second approach. Finally, it results to a bad performance for the second model.
On the other hand, our system has two drawbacks:
- 1. It only works with car place license in a specific format (only for exactly seven characters or digits license).
- 2. In our dataset, we view all "0"(character) as 0(digit), because it is hard for us to distinguish two symbols. Therefore,
our models cannot also distinguish "o" and 0 in an input image.
Our recognition system is successful. However, there are several works that we need to improve in the future such as fixing drawback we rise above and designing detection system for potential car plate
license in a image. Furthermore, thanks for the professor and the course, because it gives us an opportunity to work for the project.
Acknowledgement
We would like to thank the professor and the course TA who have been providing us help during the course. We would also like to thank Dr. Yang Yang for helping us prepare the data set and stimulating discussions.
Reference
These three papers are relevant on our project.
Teammate
Thus the assignments for every member are as follows:
- Jirong Yi: writing codes for Vanilla_CNN.py and image_to_data.m, data collection, doing experiment for the first neural network
- Ke Ma: writing codes for catch_number_plate.py, rotation.py and adding_noise.py, data collection, and final report
- Qi Qi: writing code for vanilla_resnet_v3.py, data collection, doing experiment for the second neural network
proposal for License Plate Recognition
progress report for License Plate Recognition
codes